
L’apprentissage profond (Deep Learning) permet non seulement de gagner du temps par rapport à l’apprentissage classique mais aussi a révolutionné l’intelligence artificielle grâce à l’intégration des réseaux de neurones occasionnant plusieurs techniques dont l’analyse des données textuelles avec des résultats surprenants. ChatGPT en est un exemple surprenant !
C’est le cas de l’analyse des sentiments, la génération de texte, le système de recommandation, la reconnaissance vocale, d’image et la traduction automatique.
Google et son célèbre moteur de recherche, Alexa, Siri et Cortana sont des exemples de technologies du DL capables d’effectuer de larges éventails de tâches complexes du NLP (langage naturel) difficile à accomplir par les ordinateurs auparavant.
Pour une approche classique ou traditionnelle, l’exploitation des données avec un ensemble de variables de base permet de trouver un modèle à partir de celle-ci. Cette approche permet de générer un modèle qui ne généralise pas bien où nous devons trouver les variables significatives ou non.
Pour favoriser de véritables performances et de prédiction, le Deep Learning exploite multiples couches cachées leur permettant d’apprendre et de développer des caractéristiques dont ils ont besoin. Cependant cela nécessite une quantité de données énorme.
Avec l’évolution des techniques d’IA, Le DL s’applique à plusieurs domaines comme la réalité virtuelle, les voitures autonomes, la détection des cancers, la détection des malwares, la reconnaissance faciale et vocale, l’IoT, les réseaux sociaux et les chabots.
Comme tout système d’apprentissage automatique, la représentation de mots passe par différents processus de traitement comme la vectorisation, la tokenisation, la lemmatisation, le stemming faisant appel à des algorithmes adéquats.
Outre les techniques basiques de représentation textuelle, avec des algorithmes d’apprentissage en profondeur, nous pouvons plus loin avec un niveau de complexité élevé pour résoudre les problèmes du NLP.
Pour un cas de généralisation et du traitement des données textuelles de masse, l’intervention des techniques du Deep Learning est nécessaire. Cela permet de créer des modèles qui apprennent et qui s’adaptent.
Au-delà de la représentation de niveau supérieur (Wei Di, 2018)avec le DL, la recherches ciblées et d’extraction d’informations est possible avec le Word Embedding.
Ainsi il faut penser à la vectorisation pour représenter chaque mot, d’un dictionnaire par un objet représentant un nombre réel. C’est dans ce cadre que l’outil Word2Vec qui est basé sur un algo du DL est utilisé pour détecter les similarités de mots ou le contexte en analysant d’autres mots qui l’entourent.
CNN (Le réseau de neurone convolutionnel)
En NLP, Le réseau convolutionnel CNN fait intervenir un ensemble de neurones applicable à la constitution de mot pour extraire des fonctionnalités de niveau supérieur (Elvis, 2018). On peut par cette occasion appliquer efficacement cette technique sur la traduction automatique, l’analyse ou la réponse aux questions.
Applicable dans le traitement de texte, le diagnostic des maladies, la classification d’images, CNN (Convolutional Neural Network) est l’un des RN les plus performants dans le Deep Learning.
Si vous voulez un modèle capable de voir une image et de la comprendre comme un humain, le CNN est le choix idéal. On peut compiler, entraîner notre modèle puis l’évaluer et réaliser une précision.
Modèles d’apprentissage automatique avancés pour le traitement du langage naturel
La technologie du NLP avance à grands pas grâce à l’apprentissage profond faisant intervenir plusieurs couches cachées pour le traitement des données textuelles plus complexes.
L’objectif étant de permettre à l’ordinateur de lire, comprendre et interpréter le langage humain, le NLP combine une discipline de la linguistique et de l’informatique pour parvenir à ses fins.
Avec la massification des données textuelles non structurées sur le web et les réseaux sociaux, les documents issus des organisations, les dossiers médicaux, les réactions des internautes et des clients, le NLP est plus que nécessaire dans l’analytique textuelle.
De nombreux secteurs d’activité utilisent cette technologie, ce qui fait de l’avenir du NLP plus attrayant pour les entreprises et organisations. Grâce aux puissances de calcul et des approches comme le Deep Learning, à des algorithmes plus avancés, les entreprises adoptent cette technologie. « Ces organisations adoptent les technologies analytiques avancées pour un certain nombre de raisons, notamment pour améliorer l’efficacité opérationnelle, mieux comprendre les comportements et acquérir un avantage concurrentiel. Concurrentiel » (Halper, 2017).
L’analyse du comportement des clients est un cas d’exemple.
Réseaux de neurones denses et récurrents pour le NLP
Le réseau de neurones récurrent est un type de réseau pour l’apprentissage en profondeur utilisé pour traiter des séries de données de type temporelles (séquence de mots, document texte, séquence audio) etc.
Les RNN (Réseaux de neurones récurrents) interviennent dans l’apprentissage séquentiel où plusieurs données sont combinées pour le traitement en suivant la séquence des informations.
Nous avons un algorithme contenant plus unités de couches : les couches d’entrées qui reçoivent nos données, puis ils passent par les couches cachées qui déterminent le poids, ensuite on analyse, on effectue le calcul avant d’atteindre la sortie. Ils sont utilisés dans la reconnaissance vocale et d’écriture.
Dans ce cas de figure avec l’apprentissage des données textuelles dans notre réseau de neurone, l’apprentissage se fait non seulement de manière séquentielle mais chaque neurone renvoie au neurone suivant séquentiellement. Ce qui donne à cette architecture de réseau de neurones un mémoire à court terme au fur et à mesure que les données entrent dans le réseau.
Pour résoudre cette problématique de mémoire, il faudrait faire intervenir une autre forme de réseau de neurones qui est une variante du RNN possédant un mémoire à long terme dans le traitement des données. C’est le LSTM.
Avec un modèle d’apprentissage utilisant ce type de réseau de neurones, on peut créer par l’exemple de chatbot.
Modèles de transformation NLP
Le modèle transformationnel est un type de modèle implémenté par des packages comme Tensorflow, utilisé dans l’apprentissage en profondeur et du traitement de langage naturel « qui adopte le mécanisme de l’auto-attention, en pondérant différemment l’importance de chaque partie des données d’entrée » (arti, 2022).
Pour un cas d’utilisation de la traduction automatique ou d’un résumé de texte, le modèle transformationnel est conçu pour traiter des données séquentielles dans au réseau de neurone récurrent.
Pour calculer ses données d’entrées et de sortie, il se base sur le mécanisme d’auto-attention en réduisant le temps de formation, et traitant ainsi les données d’entrée une seule fois. On comprend déjà son importance dans le monde du NLP avec cette massification de données textuelles.
Avec ce succès et outre la tâche comme la traduction automatique, le modèle transformationnel a une variété d’applications dans le monde réel. De nombreux modèles pré-entrainés comme GPT-2, BERT , XLNet et RoBERT sont aussi exploitables.
Grâce aux performances de deep Learning, traiter des images à travers le réseau de neurone conventionnel peux trouver de véritables résultats, de même que la génération de document, la reconnaissance d’entité nommée.
Modèles d’attention pour le NLP
Une des avancées de l’apprentissage en profondeur dans le domaine du traitement du langage naturel est le modèle d’attention employé par exemple dans le domaine de la traduction automatique, la classification du texte, le sous-titrage et la génération de dialogue.
Pour un réseau de neurone auto-encodeur qui manipule les images. Il a principalement deux fonctions. Il fait l’encodage et le décodage des données, la compression et la décompression à la sortie, il assure la détection d’anomalies dans des données étiquetées.
De tels cas, applicable aux données textuelles, notre modèle d’attention prédit un mot de sortie en tenant compte des vecteurs de contextes associés « à ces positions sources et à tous les mots cibles générés précédemment » (Agrawal, 2020).
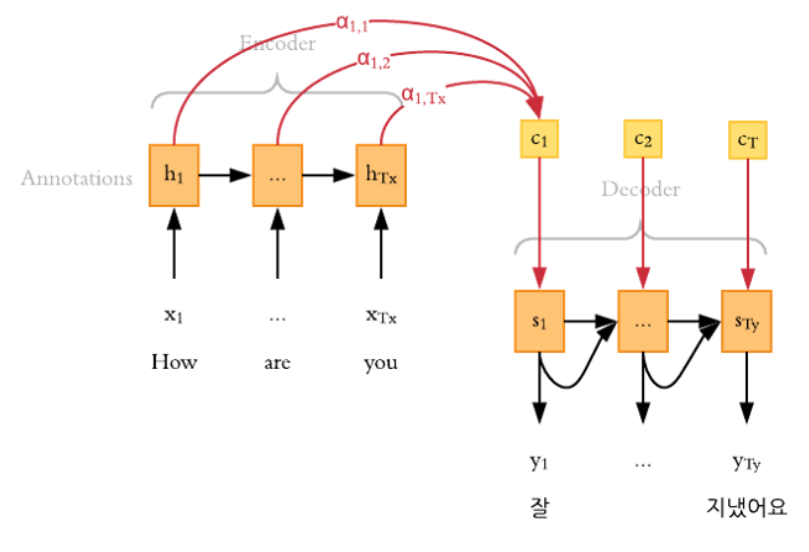
Lorsque le processus de vectorisation est réalisé, nous pouvons prendre un ensemble de données d’entrées comme des vecteurs de nombre. Ensuite on pourra appliquer différentes tâches du NLP dans le traitement de ces données, comme le Word Embedding avec des réseaux de neurones pour traiter les données séquentielles.
Il faut marteler que cette technique d’attention donne une précision et un score efficaces avec le NLP surtout dans un contexte des d’utilisation de données plus ou moins denses.
Bibliographie
Agrawal, N. (2020, 01 28). Comprendre le mécanisme de l’attention : traitement du langage naturel. Analytique Vidhya, pp. https://medium.com/analytics-vidhya/https-medium-com-understanding-attention-mechanism-natural-language-processing-9744ab6aed6a.
arti. (2022). TOP 10 DES MODÈLES D’APPRENTISSAGE EN PROFONDEUR QUI AIDERONT À FAIRE DE L’IA AVANCÉE. Analytics Insight, https://www.analyticsinsight.net/top-10-deep-learning-models-that-will-help-make-advanced-ai/.
Elvis. (2018, Aout 23). Deep Learning pour la PNL : un aperçu des tendances récentes. DAIR.IA, pp. https://medium.com/dair-ai/deep-learning-for-nlp-an-overview-of-recent-trends-d0d8f40a776d.
Halper, F. (2017). Advanced Analytics:Moving Toward AI, Machine Learning, and Natural Language Processing. Transforming Data with Intelligence (pp. https://www.sas.com/content/dam/SAS/en_us/doc/whitepaper2/tdwi-advanced-analytics-ai-ml-nlp-109090.pdf). TDWI.
Wei Di, A. B. (2018). Pourquoi le Deep Learning est parfait pour le NLP (Natural Language Processing). pp. https://www.kdnuggets.com/2018/04/why-deep-learning-perfect-nlp-natural-language-processing.html.
