
Lire, analyser, comprendre et faire les statistiques sont des techniques essentielles dans le traitement automatique d’informations linguistiques et naturels. Aujourd’hui, Internet déborde de contenus textuels, des messages électroniques sous diverses formes, structurées et non structurées. Découvrez ce qu’est le word embedding, une technique de text mining qui permet de représenter les mots par des vecteurs numériques. Apprenez comment l’utiliser avec le framework Gensim et le modèle Word2vec.
L’exploration et l’extraction de la connaissance à partir du texte est l’objectif du Text Mining. Grâce aux algorithmes du Text Mining, il est possible de traiter une grande quantité de texte, identifier les causalités, des similarités et des relations existantes entre différents concepts.
Aujourd’hui, grâce aux modèles d’intelligence artificielle, Google nous comprend. Je veux dire par là qu’il comprend le sens des mots, du texte, du son qu’il reçoit. Par exemple, lorsque nous lui lançons une requête, il répond adéquatement à ce que nous voulons.
Voilà pourquoi nous sommes à l’aise avec Google. Comprendre les besoins des internautes et les satisfaire. C’est sa force !
Voyons une des méthodes très puissante du NLP qui est le Word Embedding.
Qu’est-ce que le Word Embedding ?
Les requêtes sur Internet sont énormes. Dans notre précédente étude, il est fait mention de 7 milliards de requêtes par jour chez Google. Pour analyser et traiter cette masse d’informations, il faut utiliser des techniques, des algorithmes intelligents capables de réaliser des recherches ciblées et d’extraire les informations utiles.
Ceci entre dans le cadre de la recherche d’informations d’où le Word embedding. Comme nous l’avons vu dans le thème 1, le Word embedding ou le plongement de mots est une technique de traitement automatique des langues pour faire la représentation de mots.
Pour que la machine comprenne le sens des mots, il faut penser à la vectorisation. Ainsi, nous pouvons représenter chaque mot, d’un dictionnaire par un objet représentant un nombre réel. C’est l’encodage du mot par des vecteurs compréhensible par la machine.
Exemple concret avec la représentation contextuelle du Word Embedding
• L’extraction du sens commun des mots.
• Nous avons utilisé le Framework Gensim capable de chercher les similarités entre les mots.
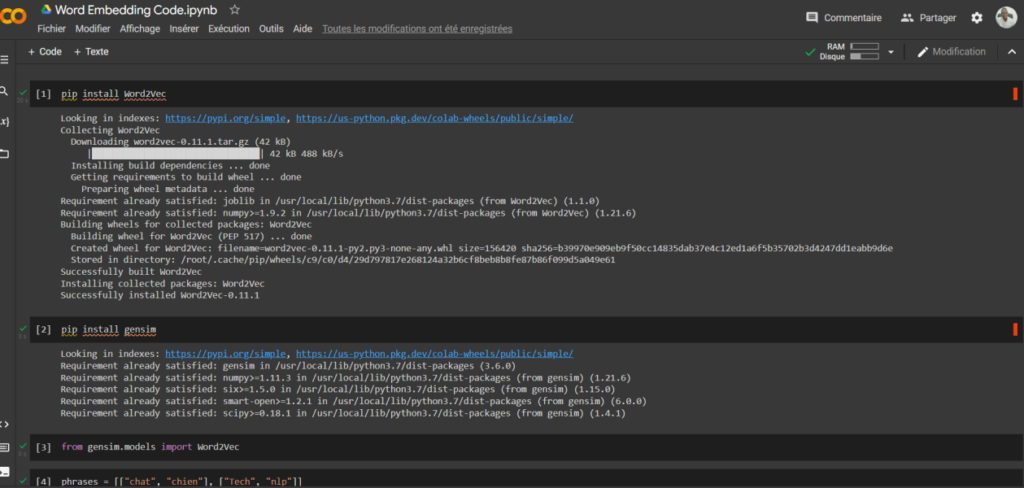
Voici une colonne de chiffre extraite à partir du mot « Chat » réalisé sur le code Google Colab (gensim et word2Vec).
Word2vec en NLP (Natural Langage Processing)
Nous avons observé dans l’exemple ci-haut une représentation textuelle en chiffre du mot chat dans un corpus de texte en utilisant l’algorithme Word2vec. Le constat est simple, c’est un outil, une technologie de calcul vectoriel qui fait partie du Word Embedding développée par Google en 2013 (Mikolov & Chen, 2015) qui permet de faire comprendre à la machine le sens des mots.
Ainsi grâce à l’apprentissage supervisé, un modèle entrainé peut détecter les similarités de mots ou le contexte en analysant d’autres mots qui l’entourent.
Le Word2Vec est applicable dans la représentation des pays et leurs capitales. L’implémentation du Word2vec qui est basé sur un algorithme deep Learning nous amène à explorer deux architectures dans la représentation de mots qui sont CBOW (Continuous Bag-0f-Words) et Skip-Gram.
Le bag-of-words ou sac de mots est une technique de calcul permettant de transformer le texte en chiffre pour le traitement. Pour exemple, pour un document qui contient un ensemble de mots (Bonjour, bonsoir). L’algorithme fait décompte en faisant l’analyse de l’apparition du mot dans le document.
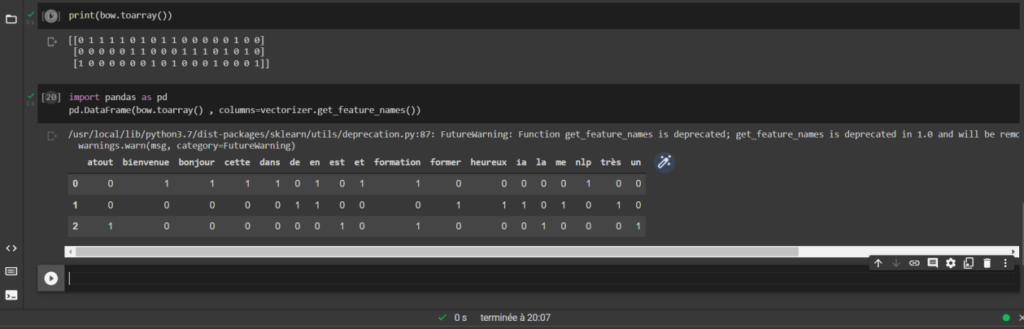
Cas pratique avec la bibliothèque Sklearn sur Google Colab.
Calcul du texte à l’aide la fonction fit et transform.
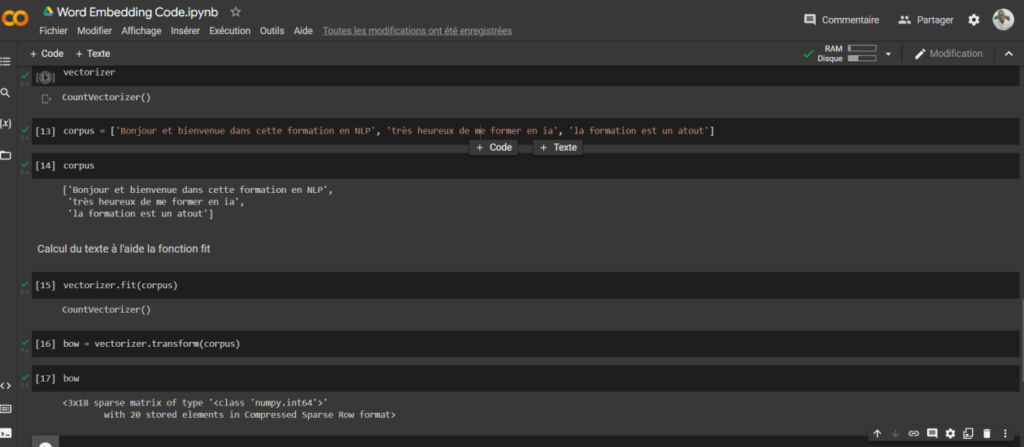
Nous observons ici la décompte avec la technique du bag-of-words. 20 mots ont été trouvé dans notre corpus. Ce sont les étapes de calcul avec sklearn et la méthode vectorizer.
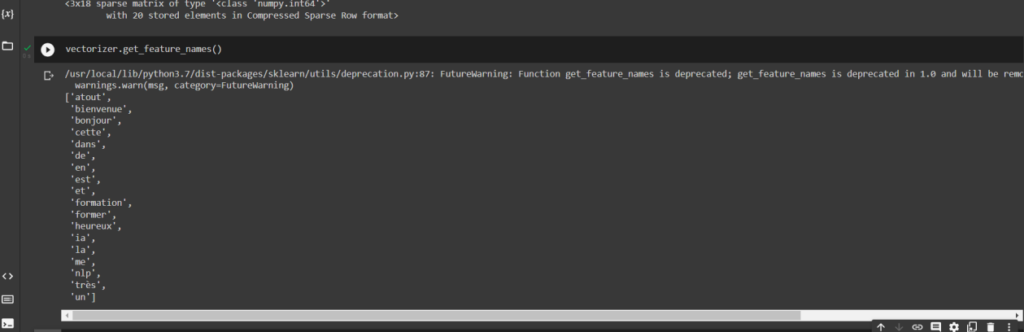
Maintenant, procédons à l’affichage. Utilisons la fonction get_features_names. Voir la capture du sac de mots.
Affichons le dénombrement dans un tableau. On peut utiliser Pandas.
Skip-Gram est une deuxième approche très différente du CBOW qui permet de produire de meilleurs vecteurs de mots pour les mots peu fréquents (Wang, 2014). De ce fait, cette méthode après entrainement (réseaux de neurones) va faire la prédiction du contexte d’un mot en le recevant en entrée.
Ce qui révèle que cette méthode n’a pas besoin que les mots soient consécutifs dans le texte même s’il peut en faire une analyse complète avant de faire la prédiction.
Character Embeddings
Grâce à l’avènement du Word Embedding en 2013, plusieurs ont été utilisé pour donner du sens à du texte, plusieurs spécifiquement aux mots comme nous l’avons vu dans les exemples précédents.
Pour aller plus loin, une nouvelle technique fut introduite. Cette fois au lieu d’agréger un mot à l’autre, est-il possible d’agréger d’un caractère à l’autre (Ma, 2018).
Ainsi, cette introduction des caractères peut s’appliquer à un système de classification du texte et de la reconnaissance d’entité nommée en tenant compte de la structure interne du mot.
Parmi les caractères utilisés, nous avons les 26 lettres, les 10 chiffres et des caractères spéciaux que nous pouvons encoder pour trouver des séquences de vecteurs à des dimensions différentes. Chaque mot étant constitué de plusieurs caractères donne une signification sémantique du mot.
De ce point de vue, « nous prenons le chinois par exemple et présentons un modèle d’incorporation de mots à caractères améliorés (CWE) » (Xinxiong Chen, 2015).
Contextualized Word Embeddings
En 2020, une enquête sur l’incorporation contextuelles fut menée par (Qi Liu, 2020) et le résultat fut impressionnant sur un ensemble de tâches en matière du traitement naturel du langage.
Comme son nom l’indique, cette technique permet de représenter des mots en tenant compte de l’aspect contexte et à la variabilité sémantique.
La représentation d’un mot basée sur son contexte permet d’englober la connaissance qui favorise le transfert de langue grâce aux modèles d’intégrations entrainés.
Techniques d’étiquetage grammatical
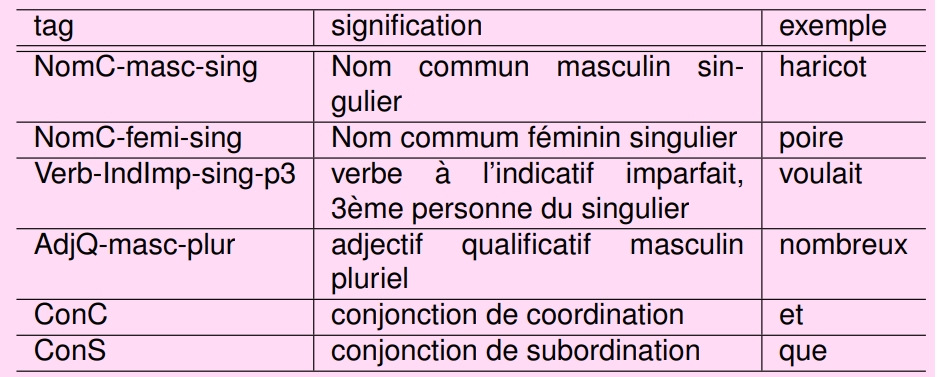
Le but de la technique d’étiquetage est d’associer chaque mot à un tag. D’autres parle de POS (Part Of Speech).
Vous vous rendrez compte que cette technique est importante dans l’apprentissage d’un modèle en favorisant la détection, l’extraction rapide d’information et la réponse à certaines questions comme le remplissage de champs d’un formulaire.
Voici l’extrait du résultat d’un entrainement d’étiquetage sur 330 étiquettes (Langlais, 2012).
Tables de correspondance, n-grams, modèles de Markov cachés
Faire Comprendre le sens des mots à la machine dans leur contexte reste la mission de n-grams. Pour cela une analyse doit être faite avant et après chaque mot afin de définir le contexte.
Définissons par exemple une phrase : Je finirai mon mémoire bientôt ! L’analyse de cette phrase en extrayant le mot « mémoire » et en le plaçant dans son contexte nous permet de comprendre sa sémantique.
C’est ce que fait n-grams, en révisant l’avant et l’après du mot pour le placer dans son contexte. Donc n-grams fait référence aux séquences continues de mots ou de symboles ou de jetons dans un document (V, septembre 2021). N étant une variable, voici le type modèle de n-grams.

Voici un exemple avec bi-gramme : « Je suis un super étudiant ».
Résultat : [‘Je suis’, ‘suis un ’, ‘un super’, ‘super étudiant’]. Il est clair ici que nous prenons deux mots à la fois.
Dans le domaine du machine Learning, le modèle de Markov est un procédé mathématique (statistiques) qui est utilisé pour modéliser des séquences d’observations qualitatives ou quantitatives (LEKOUNDJI, 2014). Si l’état dans lequel nous sommes est observable, ce modèle est de type markovien observable. Sinon nous avons un modèle de Markov caché.
Voici un exemple d’allumage d’une lampe en fonction de la météo (R, 2021). Nous pouvons ainsi une méthode de probabilité pour obtenir ce résultat.
En ce sens, le modèle de Markov est utile et applicable dans divers domaines notamment dans le traitement de la parole, l’’analyse financière (marché boursier) et la biologie (classification des gènes).
Bibliographie
Langlais, P. (2012, 11 1). Introduction aux etiqueteurs . Manning and Sch ¨utze 1999, pp. http://www-labs.iro.umontreal.ca/~felipe/IFT6010-Hiver2015/Transp/tagger.pdf.
LEKOUNDJI, J.-B. V. (2014). https://archipel.uqam.ca/7009/1/M13570.pdf. UQAM.
Ma, E. (2018, 06 21). Besides Word Embedding, why you need to know Character Embedding? Towards Data Science, pp. https://towardsdatascience.com/besides-word-embedding-why-you-need-to-know-character-embedding-6096a34a3b10.
Mikolov, T., & Chen, K. &. (2015, 05 19). Computing numeric representations of words in a high-dimensional space . Google Inc., p. https://worldwide.espacenet.com/patent/search/family/053054725/publication/US9037464B1?q=pn%3DUS9037464.
Qi Liu, M. J. (2020, 04 13). Une enquête sur les intégrations contextuelles. https://arxiv.org/, pp. https://arxiv.org/abs/2003.07278#:~:text=Contextual%20embeddings%20assign%20each%20word,knowledge%20that%20transfers%20across%20languages.
R, M. (2021). Modèles markov. https://datascientest.com/modeles-de-markov.
V, N. (septembre 2021). Que sont les n-grammes et comment les implémenter en Python ? analyticsvidhya, https://www.analyticsvidhya.com/blog/2021/09/what-are-n-grams-and-how-to-implement-them-in-python/.
Wang, H. (2014). Introduction to Word2vec and. (p. http://compling.hss.ntu.edu.sg/courses/hg7017/pdf/word2vec%20and%20its%20application%20to%20wsd.pdf). NTU CL Lab.
Xinxiong Chen, L. X. (2015, 06 23). Apprentissage conjoint des incorporations de caractères et de mots. AAAI Publications, p. https://www.aaai.org/ocs/index.php/IJCAI/IJCAI15/paper/viewPaper/11000.
