Le cerveau humain regorge de mystère. La caboche qui nous sert de cerveau est remplie de cellules interconnectées. Ces cellules sont nommées neurones, vous l’avez certainement compris, les synapses sont des liaisons d’interco qui nous assurent une fonction de cognition.
Un des principes d’innovation en matière de technologie consiste à s’inspirer de quelque chose qui existe déjà. Par exemple, un avion ressemble quelque peu à l’oiseau, on est d’accord?
De même, si nous voulons mettre en place un système informatique apte à penser, à apprendre et à résoudre des problèmes, le cerveau humain est l’exemple parfait. Du coup, notre système cognitifs est constitué par des synapses interconnectées qui transmettent de l’information sous forme d’impulsions électriques.
Partant de ce principe, les ingénieurs se sont inspirés du cerveau humain pour construire les réseaux de neurones virtuels. Chacun des neurones peut être actif ou inactif.
Est-ce une reproduction parfaite de notre cerveau ? Eh bien non ! Le cerveau humain étant une mine d’or complexe, la modélisation n’a pas été totale. Seulement une partie a été prise.
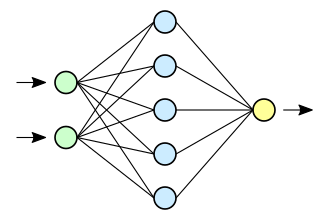
Notre réseau de neurones constitué comporte une couche d’entrée, des couches intermédiaires ou cachées et puis de couche de sortie. Le mot deep Learning vient du fait de ces couches cachées et multiples.
Voici l’origine des réseaux de neurones artificiels
Les Reseau Neurones artificiels ont fait leur première apparition en 1943. Aujourd’hui bon nombre de domaine scientifique enregistre des problèmes que nous ne pouvons résoudre avec les techniques classiques.
L’intelligence artificielle intervient afin d’ améliorer la résolution de ces types de problèmes. C’est le cas d’un diagnostic médical, la réalisation d’un système autonome, dans l’industrie 4.0 et l’aéronautique, et même les systèmes de recommandation commerciaux et les activités quotidiennes des êtres humains.f

Fonctions d’un réseau de neurones artificiel
En intelligence artificielle, l’idée est de construire un modèle s’inspirant de notre cerveau et de réaliser une machine intelligente qui apprend, et surtout qui fait des prédictions.
Dans son architecture, un réseau de neurones est constitué des couches d’entrée où nous introduisons des données d’apprentissage (texte, vidéo, audio…) qui peut être transformé en des valeurs numériques. Ces valeurs entrent dans le réseau de neurones, puis nous effectuons un calcul pour la sortie.

Dans le système de calcul réalisé, le réseau neurones artificiels trouve la sortie pour faire une prédiction.
Au fait, avant d’atteindre la sortie, plusieurs activités se passent. Cela nous amène à parler de la topologie d’un réseau de neurones que nous pouvons catégoriser en deux : la topologie en arrière où les calculs se répètent et la topologie en avant où les neurones sont interconnectés de bout en bout .
Fonction mathématique et réseau de neurones
Dans une fonction mathématique qui représente un réseau de neurones, on peut avoir plusieurs neurones. par exemple : 2 couches d’entrée et une couche de sortie combinée à des couchés intermédiaires ou cachés. Dans ce cas de figure, on fait le calcul pour trouver la fonction mathématique qui se trouve être la sortie.
Cas pratique, les réseaux de neurones avec Python
Des librairies pour Python
- Neurolab est une bibliothèque puissante et utile pour explorer les réseaux de neurones. Il est basée sur le package numpy qui permets l’exploitation des algorithmes d’apprentissage et les réseaux de neurones Python.
- Scikit-learn est une bibliothèque open source, utilisée dans l’apprentissage supervisé et non supervisé. Il entre dans l’évaluation et le prétraitement des données.
- PyTorch est une bibliothèque open source, utilisée dans l’apprentissage automatique et permet de créer des réseaux de neurones profonds et utiles dans la production.
- TensorFlow – plateforme open source permet de “ créer des modèles de machine learning pour des ordinateurs de bureau, des appareils mobiles, le Web ou le cloud.” tensorflow.org
- Keras est une bibliothèque (API) construite (il fonctionne sur la plateforme ) à partir de Tensorflow qui s’adapte à des clusters, exploite des modèles javascript, compatible avec plusieurs appareils android, ios, des API. Il est utilisé par de grandes organisations comme la NASA et YouTube. Il fonctionne dans l’apprentissage profond moderne : classification d’image, de texte… très facile d’utilisation, flexible et puissant. Fait avec du python.
Réseau de Neurone profond
Pensez-vous que le Deep Learning fait recours aux réseaux de neurones à chaque fois ? Dans la conscience de beaucoup d’ingénieurs en IA, le DL n’utilise que les réseaux de neurones dans sa technique d’apprentissage. Ce n’est pas le cas, il existe des techniques d’apprentissage DL classiques sans réseaux de neurones.
La différence réside dans les paramètres qui seront définis selon l’approche intuitive de l’humain ou de manière automatique.
Si nous prenons une architecture d’apprentissage avec une couche d’entrée avec plusieurs intermédiaires (couches cachées) dont les caractéristiques sont générées automatiquement , nous parlons du Deep Learning avec des RN.
Par ailleurs, si les paramètres sont définis manuellement. Ce n’est pas un réseau de neurones, c’est le cas du DF (Deep Forest ou forêt profonde).

C’est une technique d’apprentissage profond qui utilise des modèles non différents avec d’excellente performance dans une approche d’arbre de décision. Vous pouvez retrouver un article la dessus sur arxiv.org.
Encore une fois, pour trouver le calcul d’une sortie, on se réfère aux données d’entrées. Ainsi, une couche appelée Layer contient plusieurs neurones.
Lorsque nous observons plusieurs couches cachées, on parle de RN profond. Cela peut aller de 2 couches cachées, 3, 5, 10 etc.
Comment un réseau de neurones profond fonctionne ?
Les RN profonds sont plus complexes, avec plusieurs couches cachées, évolués et sont utilisés dans des analyses plus poussées. Cependant cela nécessite une quantité de données conséquente. Ils sont appliqués dans plusieurs domaines : VR, Voiture autonome, diagnostic médical, détection des malwares, reconnaissance vocale et faciale, robots intelligents, les chatbots, les réseaux sociaux…
Pour un cas de reconnaissance faciale par exemple, nous utiliserons un algorithme capable de reconnaître les différentes formes ainsi que les différents angles, selon la position, l’endroit et parmi tant d’éléments.
Cela suppose qu’il doit effectuer un apprentissage poussé pour le faire et surtout une quantité de données énormes avec différents aspects – angles, les formes, lieux…
Lorsque nous avons une donnée d’entrée, du texte ou une image, le neurone le reçoit et passe à l’analyse, voir les caractéristiques et s’il répond à nos attentes. C’est ainsi que nous aurons une sortie.
L’apprentissage reste concluant et ce phénomène sera reproduit la prochaine fois avec des données similaires. Cela s’appelle du raisonnement inductif.
Référons nous à son architecture, le DL fait partie du Machine Learning et aussi une partie d’un réseau de neurones.
Classer les réseaux de Neurones en DL ou pas ?
Comme je l’ai tantôt, si les caractéristiques sont extraites et apprises automatiquement : c’est un apprentissage profond.
Sinon, avec les caractéristiques déterminées manuellement : c’est un apprentissage classique.
Mais principalement, le DL se fait avec les RN, et donc il existe plusieurs types de RN :
- CNN – Convolutional Neural Network – est un réseau de neurones adapté à la classification d’images, vidéo. Vous pouvez former et entraîner votre modèle en quelques lignes de commandes sous Python.
Le CNN est du type FNN (forward), avec une connexion en avant, très utilisé dans le visuel adapté aux images, des vidéo. Pour analyser une image, on peut le réaliser sous plusieurs dimensions, 2 ou 3D selon les pixels, les couleurs, le nombre de couches. On analyse les différentes caractéristiques de l’image puis on pourra généraliser.
Très efficace dans l’apprentissage Profond, dans cet article sur comment les Réseaux de neurones à convolution fonctionnent, il est fait mention du principe de fonctionnement des CNNs dans la résolution des problèmes en utilisant l’IA. La reconnaissance des éléments, leurs utilités dans le tri d’image par exemple via plusieurs outils.
- LSTM : Long-short-Term Memory – est un réseau de neurones adapté aux données séquentielles – texte, image et de l’audio…
Le LSTM de type récurrent est un concept d’apprentissage séquentiel. Plusieurs données sont combinées en vue de traitement en suivant la séquence des infos.
Nous avons un algo contenant plus unités de couches : les Couches entrée reçoivent les données, puis passe par les Couches cachées qui déterminent le poids, on analyse , le fait calcul avant d’atteindre la sortie. On peut l’utiliser dans la reconnaissance vocale et d’écriture.
LSTM fonctionne comme un RN récurent avec un transfert de données. il y a plusieurs cellules comportant plusieurs portes ou les infos entrent et sortent. Ces infos sont analysées et les pertinentes sont retenues en vue d’une prédiction. Encore qu’il faut aussi une quantité énorme de données pour mieux apprendre.
- Les Autoencodeurs est un réseau de neurones qui entre dans l’apprentissage non supervisé. De ce fait, ils assurent l’encodage et le décodage, la détection d’anomalies et le bruitage des images et des projections dimensionnelles des données.
L’intelligence artificielle et la généralisation dans les prédictions

Aujourd’hui l’objectif principal de l’IA consiste à faire de la généralisation. C’est-à-dire permettre aux machines comme l’humain d’être capables de performer dans plusieurs domaines. Une ambition colossale !
Pour atteindre cet objectif de généralisation, il faut :
- Utiliser plusieurs couches cachées – varier leurs connexions, des nœuds;
- Utiliser une quantité énorme de données;
- Choix de la bonne architecture (nombre de couches, prédiction, le domaine, type de data);
- Faire de prédictions correctes;
- Désactiver des unités ( neurones) temporairement;
En résumé, nous avons vu que les réseaux de neurones artificiels sont schématiquement conçus à la base dans une modélisation du fonctionnement du cerveau humain. Avec son caractère mystique, seule une partie (l’interconnexion des synapses) sont modelisés pour l’apprentissage des modèles d’intelligence artificielle.
Ces réseaux de neurones traitent les données grâce à des fonctions mathématiques qui reçoivent des valeurs numériques pour nous donner des résultats, faire des prédictions : classification, régression, regroupement… c’est du machine learning.


Vous etez un bon instructeur,j apprecie beaucoup vos articles