
Grâce aux bibliothèques et au langage du machine Learning comme Python, le domaine d’application du NLP s’élargit et le traitement de données devient de plus en plus simple. Des chat bots, l’analyse des sentiments, la reconnaissance vocale, l’extraction des mots et plusieurs autres domaines d’utilisation intéressants les uns que les autres.
Nous observerons un certain nombre de bibliothèques, la plupart en python qui facilitent le traitement des données textuelles non structurées en NLP. Cela se passe avec un certain nombre de processus du prétraitement qui sont des techniques comme le stemming, la lemmatisation, la tokenisation.
La bibliothèque NLTK pour le NLP
NLTK ou Natural Langage Toolkit est un package python qui figure parmi le top bibliothèques utilisées dans le traitement automatique du langage naturel. On peut le considérer comme une API du Text mining.
Le prétraitement des données est un des aspects fondamentaux du deep Learning. NLTK assure cette tâche afin d’être prêt pour l’analyse du texte. NLTK prend en charge les fonctionnalités de classification, de tokenisation, de radicalisation, de balisage, d’analyse et de raisonnement sémantique (NLTK).
Pour notre prise en main, voyons comment configurer cette bibliothèque si riche avec python.
Installation du NLTK
Grâce à l’installeur PIP on peut installer NLTK via Anaconda qui est un véritable gestionnaire de packages pour les dépendances dans notre machine physique. Installation d’Anaconda et lancement de Jupiter Notebook.
Puisque le package NLTK fonctionne avec Python. Nous avons installé ce dernier.
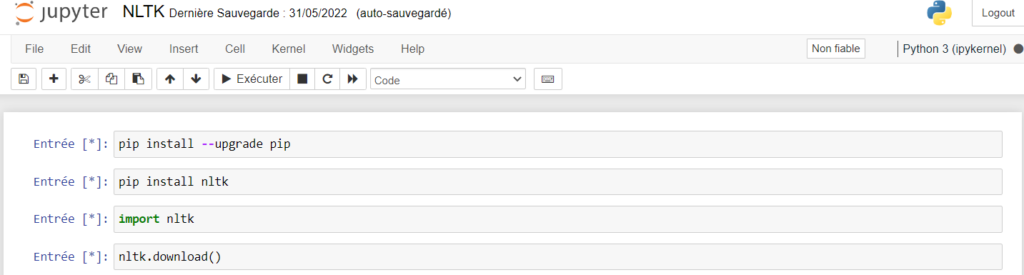
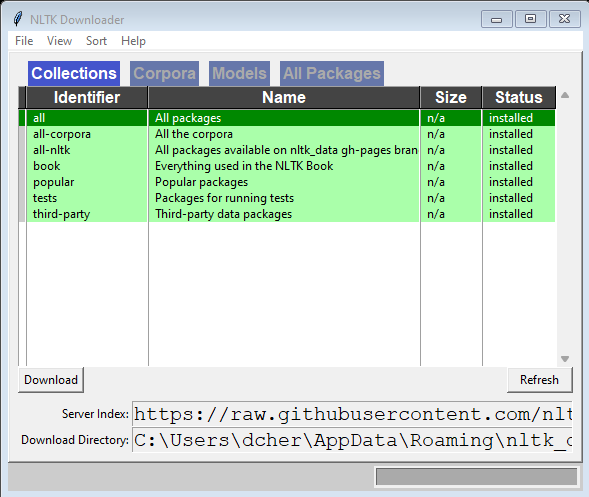
Pip Install nltk Import nltk Nltk.download()
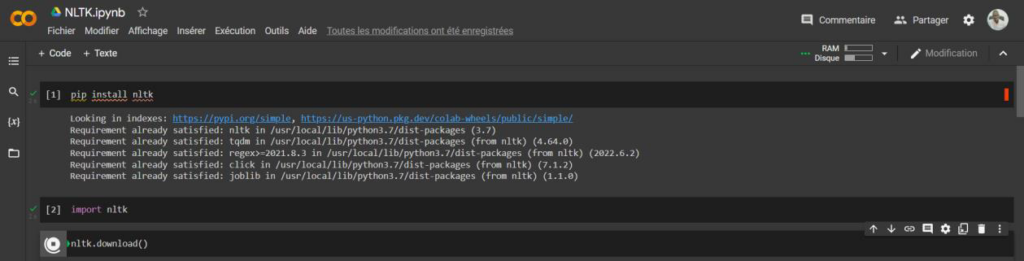
On peut réaliser cette tâche aussi sur Google Colab.
Configuration du NLTK
Dans cette configuration, nous expérimentons une technique de tokenisation avec un exemple d’analyse de texte avec NLTK. Cela dit, on peut effectuer une tokenisation par mot ou par phrase dans la transformation de nos données non structurées.
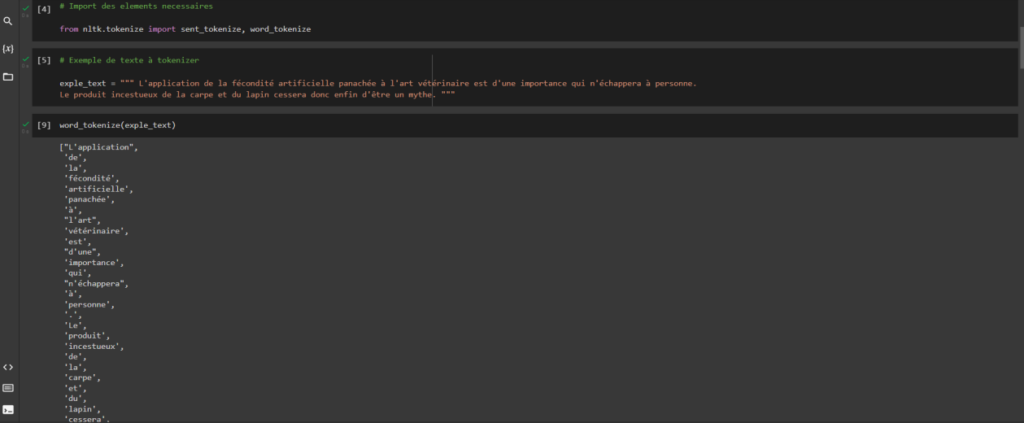
Afin de pouvoir segmenter par mot ou par phrase les données disponibles, faisons un import des tokenizers.
Voyons le code de la tokenisation par phrase qui nous donne une liste de chaines. Voici notre exemple de texte :
« » » Bonjour et bienvenue dans cette formation en NLP. C’est un domaine hyper riche avec une panoplie de bibliothèques comme nltk, spicy. Vous pouvez y faire beaucoup de projets comme l’analyse des sentiments ou la reconnaissance vocale. Bonne formation ! « » »
Voici le résultat dans Google Colab. Nous observons une segmentation par phrase qui nous ramène chaque fois à la ligne.

Terminons sur cet exemple de tokenisation par mot qui nous donne liste de mot.
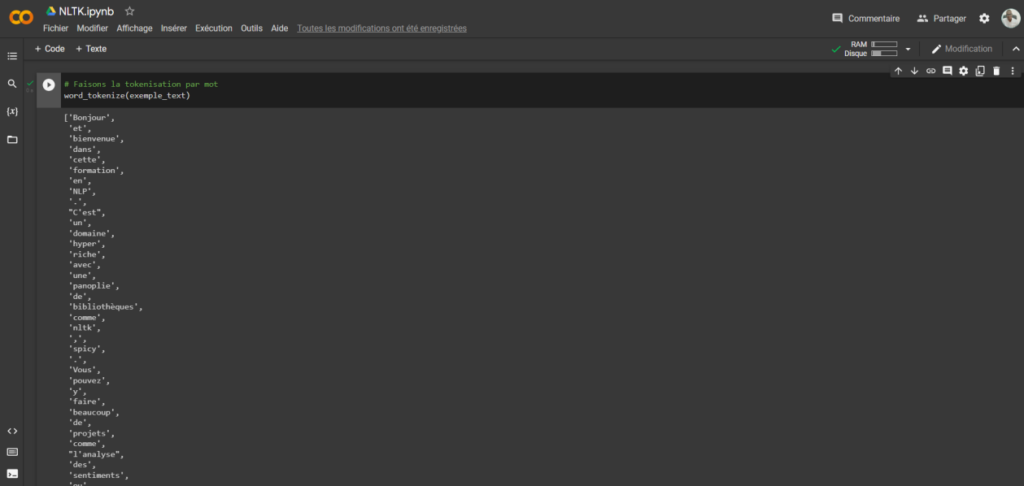
Cette segmentation affiche une liste de mots comme « y », «. », « ‘ » qui peuvent être des mots vides. Nous pouvons appliquer un filtrage.
Cas pratique avec NLTK
Prendre des données textuelles et les transformer en modèle nécessite plusieurs étapes dont la tokenisation, le stemming, la lemmatisation et d’autres méthodes que nous avons déjà vues dans les thèmes précédents.
Pour nettoyer nos données non structurées, nous allons passer par la tokenisation des mots, qui consiste à diviser, à segmenter nos paragraphes, phrases en des petites unités appelées tokens.
« Je suis très heureux aujourd’hui »
La tokenisation de cette phrase permet d’identifier chaque mot et permettre la compréhension générale grâce au NLP.
Tokenisation avec NLTK
Avec notre package écrit en python, nous avons des modules tokenize() qu’on peut utiliser pour tokeniser les mots (word_tokenize()) ou les phrases(sent_tokenize()).
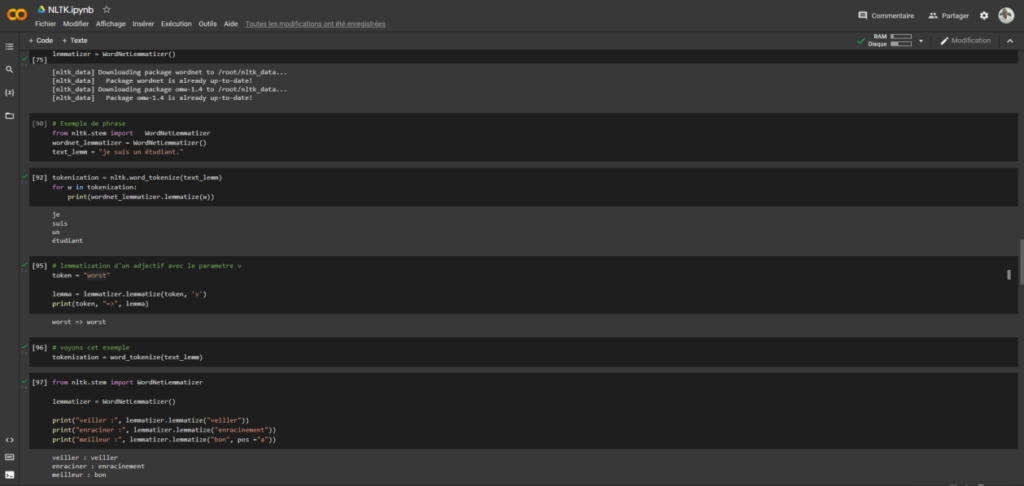
Lemmatisation avec nltk
Voyons maintenant la lemmatisation qui est une étape intéressante dans le traitement de données textuelles en prenant différente forme d’un mot pour le ramener à sa racine sans oublier le contexte. Ceci est très évident dans les moteurs de recherche.
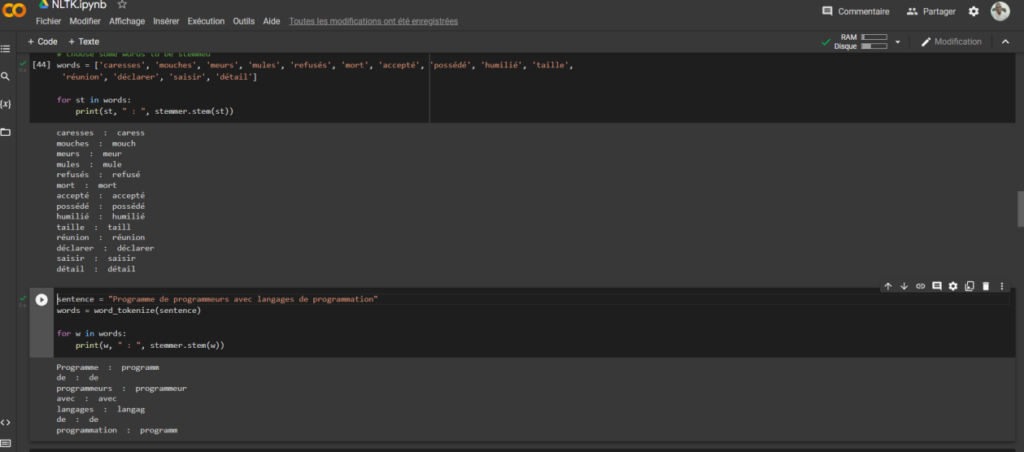
Le stemming avec nltk
Si vous voulez obtenir le mot racine d’amour ou des mots dans une phrase, la technique de streaming est votre choix. Elle permet ainsi de faire une normalisation même s’il y a d’autres facteurs qui ne sont pas pris en compte.
La bibliothèque SpaCY pour le NLP
Très utile dans le traitement des conteneurs de langue, Spacy est une API python open source utilisée dans le Text mining et qui exploite beaucoup de fonctionnalités, notamment la classification des documents, la reconnaissance d’entité nommée et la tokenisation.
Ce sont entre autres des techniques sur lesquelles on peut s’appuyer pour utiliser ce package. Il a été développé par Matthieu Honnibal depuis 2015 (Wikipédia).
Pour l’exploiter, plusieurs modèles de réseaux de neurones existent dans diverses langues et des extensions (Thinc, displaCy, CSS, SVG).
Installation et analyse de différents modèles de langues avec Spacy
Avant de faire quoi ce soit, pensons à installer le package Spacy sous Anaconda avec Jupiter Notebook, puis sur Google Colab. Nous prenons référence sur la documentation Spacy (Spacy, 2016-2022). Voir capture.
Après installation, téléchargeons un modèle de langue en français pour notre analyse avant de commencer. Après nous ferons un import rapide du package.
Utilisons cette commande: python -m spacy download fr_core_news_sm
Importons le package Spacy et chargeons la langue. Voir capture.

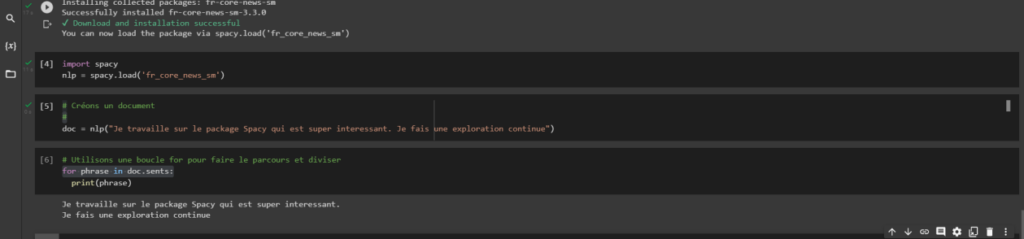
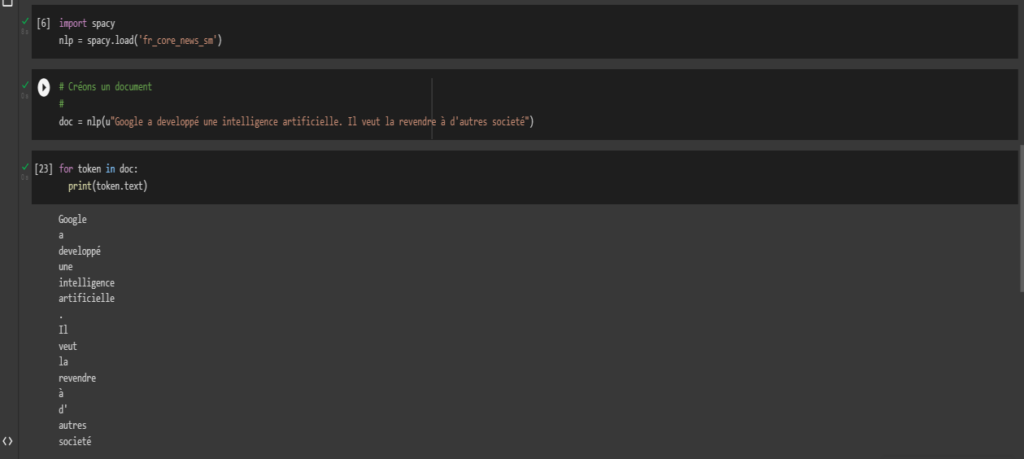
Créons maintenant un corpus contenant une chaine. Notre objectif est par exemple de pouvoir diviser un paragraphe s’il existe en phrase, une phrase en mot. Voyons les captures.
Donnons à Spacy une phrase à analyser qui sera stockée dans une variable doc.
Voici le code :
doc = nlp(‘ Je travaille sur le package Spacy qui est super intéressant. Je fais une exploration continue’)
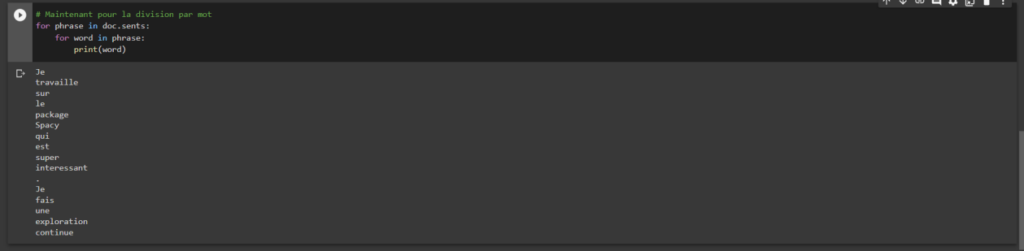
La tokenisation avec Spacy
A l’instar du package NLTK, la tokenisation est possible avec Spacy. Cela permet d’éclater une phrase par exemple.
La reconnaissance d’entité nommée avec Spacy
NER ou Name Entity Recognition permet d’analyser les entités nommées dans un d’informations. C’est extrêmement important.
Voyons l’analyse de cette phrase.
doc = nlp(« Je travaille à UQAR au Canada sur le package Spacy qui est super interessant. Je vis à Lévis. »)
En fin de compte, NLTK a plus de paramètres dans le traitement des chaines, parfait pour la recherche avec plus de possibilité de personnalisation mais Spacy est plus spécifique et est orienté objet.
Textacy pour le NLP
À l’instar des bibliothèques NLK et Spacy, Textacy est aussi une bibliothèque python qui relève d’ailleurs de Spacy et utile dans le prétraitement, le nettoyage et la normalisation du texte.
Dans sa documentation, nous relevons que TextaCy a plusieurs fonctionnalités intéressantes en NLP notamment la tokenisation, la vectorisation de documents, l’extraction des données structurées, le nettoyage, l’exploration du texte brut et le calcul de statistique de visibilité (DeWilde, 2021).
Pour grandement exploiter les fonctionnalités de ce package, il est intéressant d’installer certaines dépendances comme matplotlib pour la visualisation par exemple.
Il serait maintenant nécessaire d’installer un modèle de langue puisque Textacy relève de Spacy. Faisons un import du package.

Installation de Textacy
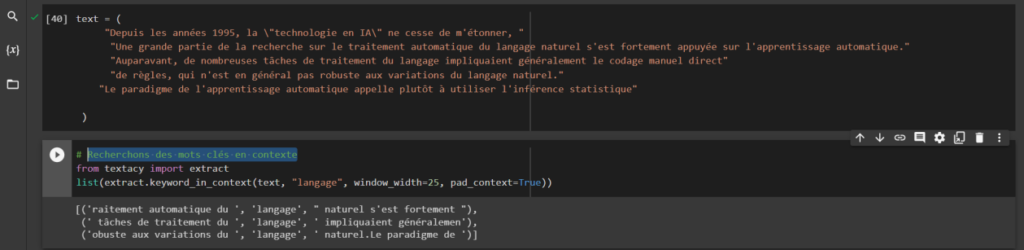
Faisons un import et créons un exemple texte à analyser. Recherchons des mots clés en contexte « Langage ». Voici la capture.
Maintenant faisons une suppression de la ponctuation et le texte en majuscule.

Nous observons que notre texte n’a plus de ponctuation et des caractères spéciaux. Plus encore, Textacy est utile dans le traitement des documents, calcul des statistiques, l’identification des termes clés comme nous l’avons vu. Avec Spacy comme référence, les possibilités deviennent énormes.
Bibliographie
DeWilde, B. (2021). textacy : PNL, avant et après spaCy., (p. https://textacy.readthedocs.io/en/latest/).
NLTK, D. (s.d.). Courses that use NLTK (https://docs.google.com/document/d/1eYubSwLkpB7ZgfQVxxAwgsmAqS__BRfbMyP9qV6ngD8/edit=.
Spacy. (2016-2022). Install Spacy.
Wikipédia. (s.d.). SpaCy. https://en.wikipedia.org/wiki/SpaCy.
